
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- BFS
- Game Data Analysis
- 그리디
- 정렬
- classification
- 알고리즘
- 백준
- ML
- 구현
- DP
- Queue
- 자료구조
- datascience
- Python
- Deeplearning
- anomaly detection
- p-value
- 스택
- Journal Review
- AA test
- Machine learning
- Anti Cheat
- c++
- 중앙갑
- Stack
- 큐
- 통계
- cs231n
- 7569번
- 딥러닝
- Today
- Total
Software Hyena::
[저널리뷰] - An Empirical Study of Anomaly Detection in OnlineGames 본문
[저널리뷰] - An Empirical Study of Anomaly Detection in OnlineGames
bluehyena 2022. 5. 4. 17:20Journal Reveiw of Game Anomaly Detection
논문제목 : An Empirical Study of Anomaly Detection in OnlineGames
리뷰했던 논문들에 공통적으로 citation이 된 논문이 바로 이 논문이다. 제목부터 Empirical Study라고 하니 많은 노하우가 담겨있을것이라 생각하여 이 논문리뷰를 진행하였다.
Abstract
Anomaly Detection의 Game분야의 적용은 매우 적게 연구되고 있다. 이 논문에서는 online game에서의 anomaly detection에 대한 경험적인 내용들을 서술했다. 4개의 Unsupervised Learning Technique이 사용되었고 모든 실험은 VNG사의 2개의 실제 온라인 게임 데이터와 하나의 인공데이터셋으로 진행되었다. 결과는 anomaly detection의 게임분야 적용가능성이 있음을 보여준다.
Introduction
과거부터 이어져온 cheat detection의 방법은 특정한 하나의 소프트웨어만을 제제할 수 있었다. 이런 rule based method는 알려진 cheating technique에는 대응이 쉽지만, 변화가 빠른 cheat에는 대응이 힘들다. 이 때문에 anomaly detection이 등장한 것 이다. 기계 학습에서 이상 감지 접근 방식은 데이터에서 예상한 값을 따르지 않는 샘플 찾기를 목표로 합니다.
이 논문에서 주요하게 다루고 있는 내용은 3가지이다.
- 성능평가에 Non-linear classifier의 적용, Logistic Regression 보다 좋은 성능.
- Parametric model의 적용. 모델이 더 빠름.
- 모든 방법론을 더 넓은 데이터셋에 대해서 평가.
Related Work
Game Cheating Detection Techniques -> 3개 그룹으로 나눌 수 있음.
1. 게임룰에 근거한 그룹
-> 어떤 게임룰이 어겨지면 Cheating User로 판별
-> Black List 활용
-> 많이 알려진 Cheating 기법들을 Black List에 올리고 특정게임에서 이런 현상이 발견시 Cheating으로 판별
-> 최근 빠르게 변화하는 핵에 대응하기는 힘듬
2. 게임 플레이어의 데이터를 바탕으로 통계분석 그룹
-> 확률론을 기반으로 한 score 로 판별하는 방법, Server-sided한 방법
3. Anomaly Detection 에 기반한 그룹
-> 통계분석의 확장버전
-> 현재 연구가 많이 진행되지 않음.
이 논문은 T. T. Nguyen, A. T. Nguyen, T. A. H. Nguyen, L. T. Vu, Q. U. Nguyen, and L. D. Hai, “Unsupervised anomaly detection in online game,” in Proceedings of the Sixth International Symposium on Information and Communication Technology, Hue City, Vietnam, December 3-4, 2015. ACM, 2015 를 바탕으로 확장시켰다.
Methods
Anomlay Detection Techniques
- Local Outlier Factor
- Kernel Density Estimation
- K-Mean
- Gaussian Mixture Model
Local Outlier Factor (LOF)
Anomaly Detection 의 baseline.

쉽게 말해 LOF 값은 특정 object가 outlier가 될 정도를 나타내는 값이다.
Kernel Density Estimation (KDE)
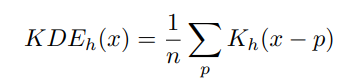
데이터 샘플의 Density는 위의 공식에 따라 계산이 된다.
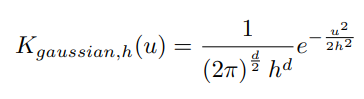
KDE에서 올바른 커널을 적용하는 것이 중요한데 online game anomaly detection 에는 가우시안 커널이 적용되었다.
K-Means
Clustering 의 가장 대표적인 방법, N개 데이터를 K개의 클러스터로 분할하는 것이 목표. Centroid를 Update 해 가며 K개에 대한 Cluster를 만들어 간다. Anomaly Detection에서 Clustering은 normal data는 large cluster에 속해있고, anomalies는 small cluster에 있다는 가정이 바탕이 된다.
Gaussian Mixture Model (GMM)
GMM은 모든 데이터 포인트가 생성된다고 가정하는 확률모델이다.
+ GMM의 경우는 이해가 어려웠고 아직 완전히 이해를 하지 못했다.. 정리가 잘 된 다른 블로그를 첨부한다. 추가 공부가 필요할 듯 하다. 어쨋든 GMM도 Clustering에 사용될 수 있다.
https://sanghyu.tistory.com/16
GMM(Gaussian Mixture Model,가우시안 혼합모델) 원리
개인공부용 블로그로 이곳의 내용에 개인적으로 추가정리하였다. 가우시안 분포는 데이터를 분석하는 데 있어서 중요한 여러 성질을 가지고 있지만, 실제 데이터셋을 모델링 하는데에는 한
sanghyu.tistory.com
Evaluation of Anomaly Detection
과거 label된 data에 대해서만 성능 평가가 이루어졌음.
즉, label되지 않은 현실세계의 문제에 대해 적용이 잘 되지 않음.
선행연구의 문제점이 classification의 경계가 nonlinear한 경우에서 발생한다. 선행연구는 performace evaluating에 linear (logistic regression) 를 사용했다. 성능 측정에는 F-score가 사용되었고 F-score는 높을수록 성능이 좋은 것 이다. + 이 논문에서는 non-linear classification들을 적용했다.
Experimental Settings
2세트로 분할.
1세트 : classification algorithm 의 anomaly detection성능을 비교하여 적절한 알고리즘을 선택한다.
artificial 한 labeled dataset을 만들었고 LR, SVM, KNN, RF에 대해 성능을 테스트했다. 모두 scikit-learn의 packet을 활용했다.
+ 자세한 파라미터 세팅은 G. Hackeling, Mastering Machine Learning with scikit-learn. Packt Publishing Ltd., 2014. 에서 확인할 수 있다.
2세트 : 온라인게임에서 anomaly detection의 성능을 측정하였다.
2개의 VNG사에서 출시한 온라인 게임 (JX2, Chan)에 대한 데이터로 성능을 측정했다.
JX2의 경우 선행연구와 feature수는 동일하고, Chan은 number played games, the number of won games, the amount of money gained and lost로 총 4개의 feature를 추출하였다.
파라미터 세팅
LOF factor : 10
KDE bandwidth : 1
K-means : JX2 15 cluster, Chan 6 cluster
GMM : Gaussian components 2~6
LOF, KDE, GMM은 1퍼센트의 abnormal user를 detect 해내었다.
K-means 의 경우 ranking user가 베이스가 아니라서 유저가 anomalous한지에 대한 척도가 반드시 정의되어야 한다. 이 논문에서는 단순히 적은 클러스터에 속한 유저가 abnormal하다고 판단했다.
(JX2의 경우 t = 80, Chan의 경우 t = 30으로 설정되었다)
Results and Discussion
Verifying Evaluation Techniques

4개의 Classification에 대한 결과이다. 빨간색으로 표시된 부분이 Abnormal Sample로 분류된 부분이다.
LR은 좋지 못한성능을 보여준다. 애초에 Linear Function 이라서 놀랄만한 결과는 아니다.
대조적으로 SVM, KNN, RF의 성능은 훨씬 좋게 나타났다. KNN, RF > SVM로 나타났고 SVM의 경우 대부분의 Classification을 해내었지만 가운데부분을 해내지 못하는 모습을 보여주었다. KNN, RF는 하나를 제외하고 잘 분류한 것을 볼 수 있다. 이 결과를 통해 LR과 같은 Linear를 선택했을 때 결과가 크게 잘못 될 수 있음을 확인할 수 있다.
Performance of Anomaly Detection Techniques
측정지표 3가지
1. F-score
2. 각 방법별로 detect된 abnormal user의 수
3. 알고리즘의 computational time
Accuracy는 F-score로 측정했음.
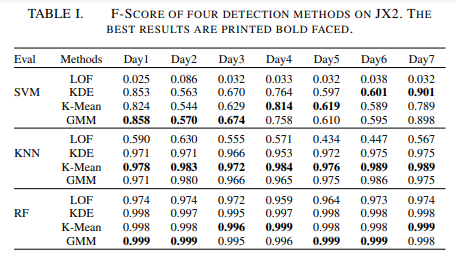
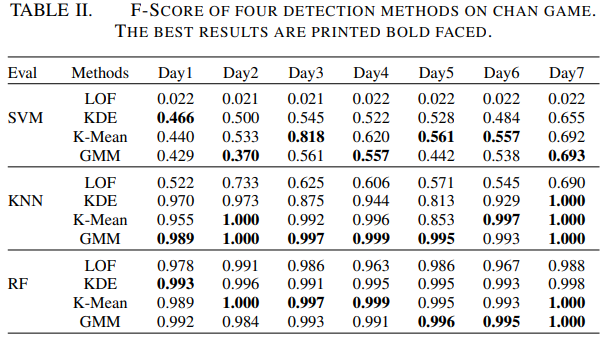
LOF를 제외하고 JX2에서 anomaly detection 방법이 잘 적용됨을 확인 할 수 있었음. 전체적으로 K-means 와 GMM이 KDE보다 살짝 더 좋은 성능을 보여주었음. 대부분의 실험에서 최고의 결과는 K-means나 GMM이었음. 오직 몇 케이스에서만 KDE가 좋은 성능을 보여주었음. 또, LOF를 보았을 때, RF가 모든 데이터셋에 대해 성능이 좋음을 확인할 수 있음.
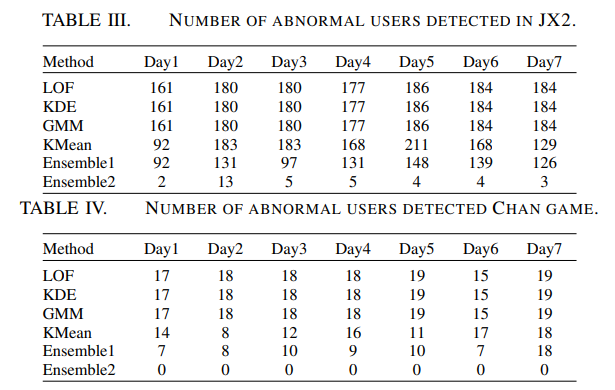
Ensemble1 은 KDE, K-means, GMM으로 detected 된 것을 의미하고, Ensemble2 는 LOF, K-means, GMM으로 Detected 된 것으로 의미한다. K-means 로 측정된 것은 Abnormal과 가장 흡사했다. KDE, K-means, GMM이 대부분의 abnormal user를 찾았음을 알 수 있다. 하지만, Ensemble2의 경우는 매우 적은 수를 찾았음을 볼 수 있다. 이 표는 앞서 LOF의 성능이 왜 좋지 않았는지 알 수 있는 자료가 될 수 있다.
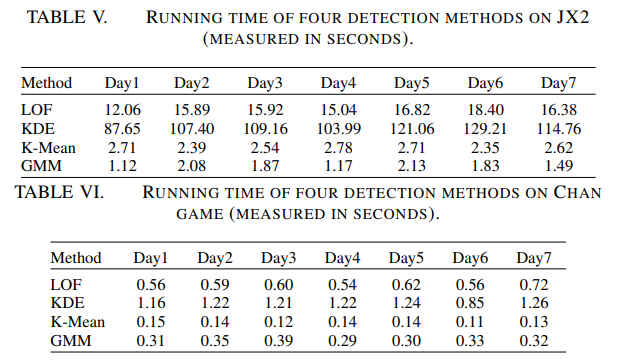
마지막 Metric은 running time이다. 모든 실행은 같은 컴퓨터로 진행했다.
- LOF, KDE가 K-means, GMM보다 훨씬 느림을 알 수 있음.
- 특히 JX2에서 LOF는 10배가 느린데, KDE는 K-means, GMM보다 100배가 느림을 알 수 있다.
- LOF, KDE는 Online Detection에 적용할 수 없다.
선행연구에서 KDE가 가장 좋다고 했었는데, K-means, GMM이 더 적합한 모습이다. 또, parametric model이 non-parametric model보다 빠르다. 따라서 parametric model이 online big dataset problem에 적합하다고 할 수 있다.
Conclusions And Future Work
- 비지도의 성능을 평가하는 더 나은 방법을 찾아야 한다.
- 결과가 K-means가 가장 좋은 성능으로 나타났는데, K-means는 cluster의 수와 같은 파라미터에 따라 성능이 크게 좌우된다. 따라서, hierarchical clustering algorithm과 같은 알고리즘을 적용하여 k-means 처럼 predefining 해야하는 parameter를 없애는 것이 좋을 수 있다.
- 실용적인 측면에서 이 anomaly detection method를 다른 게임에도 적용할 수 있다.



